
Capacity Planning (Continuação)
Agora que conhecemos a teoria para a realização de um projeto capacity planning, vamos analisar quais as métricas devem ser coletadas para cada camada que constitui o sistema computacional.
Primeiramente, temos que definir thresholds que indicam níveis de conforto satisfatórios, por exemplo 50 GB de redo diário. Ultrapassando esse nível, os tamanhos dos arquivos têm de ser reajustados para manter o tempo de leitura recomendado pelo Oracle (15 a 30 min).
Depois disso, será necessário colidir as métricas do Oracle com as métricas coletadas pelos outros componentes do sistema computacional. As métricas que devem ser coletadas são:
i) CPU: utilização, run-queue, context switches (voluntárias e involuntárias), interrupções, system calls;
ii) Storage: Número de IOPS/second, Queue Depth, Tamanho de IOPS, Tempo de resposta, throughput;
iii) Filesystem: crescimento e tempo de resposta;
iv) Memória: memória física consumida, swap in/out e Page faults;
v) Rede: Throughput e detalhes do netstat –s e kstat; e
vi) Servidor de aplicação (supondo IIS): time-taken, bytes-sent, bytes-received, status, cs-uri-stem, cs-uri-query, cs(cookie), cs(referrer).
Do monitoramento do servidor de aplicação, podemos retirar as informações plotadas na figura 4:
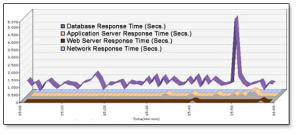
As métricas que devem ser coletadas para uma análise detalhada do banco de dados:
- Users (transactions, logons, parses);
- Redo activity;
- Temp activity;
- Tablespace e espaço usado pelos objetos;
- Pga usage;
- Sga usage;
- Parallel Operations;
- I/O Operations; e
- File Stats e Temp Stats.
Para Wait events:
Analisar os top waits events, events idle e parallel (PX*) waits (se houver), conforme pode ser visto na figura 5:

A decomposição do tempo de resposta mostra que events idle e parallel não são significativos no dia analisado desta base. Então vamos detalhar rapidamente os principais wait events plotados na figura 5:
- CPU: tempo gasto de CPU para processamento das operações
- Db file scattered read: tempo gasto com leituras multiblocks
- Db file seqüencial read: tempo gasto com leituras single-blocks
- Buffer busy waits: este evento indica uma contenção (problema de lentidão) e análise deve ser aprofundada para que seja descoberta se esta contenção ocorre, por exemplo, em um bloco de índice ou de dados, ou até no header do bloco e para cada um destes casos há uma solução diferente que são melhor explicada através do metalink: Case Study: Buffer Busy Waits Issue [ID 358303.1].
Após a coleta de todas as métricas citadas acima deve se montar tabelas com a sumarização dos dados para cada servidor e BD monitorados e os thresholds definidos juntamente com a área de negócio.
Darei mais exemplos no próximo post de como fazer a correlação entre negócio e hardware.
Abraços
José Eduardo Fiamengui Jr
